
Building a Resilient AI Bot for My Portfolio
Most developer portfolios are static pages — a list of projects, a contact form, and not much else. The question that drove this project was straightforward: can a portfolio itself demonstrate production-grade engineering?
This article documents the architecture of "Richard", an AI-powered conversational assistant embedded directly into my portfolio site. It covers dual-provider failover, LLM tool orchestration for real-world side effects (email delivery), modular React state management, rate limiting, and voice input — the same patterns used in production systems at scale.
Core Competencies Demonstrated
- LLM Failover Architecture — Primary/fallback provider pattern with zero user-visible interruption
- Tool Calling / Function Calling — AI-triggered server-side actions (email via NodeMailer)
- React Custom Hooks — Decoupled state management (
useGeminiAgent,useSpeechRecognition,useSound) - Rate Limiting — IP-based abuse prevention (5 req/min, 429 response)
- Voice UI Integration — Web Speech API with silence detection and auto-restart
- Next.js API Routes — Serverless backend handling multi-provider orchestration

System Architecture
Before diving into each component, here is how the pieces fit together:
┌─────────────────────────────────────────────────────────────┐
│ Browser (Client) │
│ │
│ ┌──────────────────┐ ┌────────────────────────────────┐ │
│ │ useSpeechRecog. │──│ useGeminiAgent │ │
│ │ (Voice Input) │ │ (State: messages[], provider) │ │
│ └──────────────────┘ └──────────┬─────────────────────┘ │
│ │ POST /api/ai │
└───────────────────────────────────┼─────────────────────────┘
│
┌───────────────────────────────────┼─────────────────────────┐
│ Next.js API Route (/api/ai) ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Rate Limiter (5 req/min/IP → 429) │ │
│ └─────────────────────┬───────────────────────────────┘ │
│ │ │
│ ┌────────────▼────────────┐ │
│ │ Groq (Primary) │ │
│ │ Llama 3.3 70B │ │
│ │ ~300ms inference │ │
│ └────────┬───────┬────────┘ │
│ OK ───┘ └─── Error │
│ │ │ │
│ ▼ ▼ │
│ Return reply ┌──────────────────┐ │
│ provider:"groq" │ Gemini (Fallback) │ │
│ │ Gemini 2.5 Flash │ │
│ └────────┬─────────┘ │
│ │ │
│ Return reply │
│ provider:"gemini_failover" │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Tool Call: send_message_to_ullas │ │
│ │ → NodeMailer → Gmail SMTP → Developer inbox │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
1. System Prompt Design: Constraining LLM Output
Problem: Unconstrained LLMs produce verbose, unfocused responses. A portfolio chatbot that outputs walls of text creates a poor user experience and wastes tokens.
Decision: The system prompt enforces strict behavioral rules — a maximum of 2 sentences per reply, simple analogies for technical concepts, and a specific conversation flow for contact requests.
Tradeoff: Aggressive brevity occasionally clips nuanced answers. This is an acceptable tradeoff for a portfolio assistant where speed and personality matter more than depth.
2. Dual-Engine Failover: Groq Primary, Gemini Fallback
Problem: Relying on a single LLM provider introduces a single point of failure. Provider outages are unpredictable and can last minutes to hours.
Decision: The service implements a primary/fallback pattern. Groq (Llama 3.3 70B) serves as the primary engine with inference latency averaging under 300ms. On any Groq failure, the error is caught and execution falls through to Google Gemini 2.5 Flash, with no user-visible interruption.
// Primary attempt with graceful fallback
if (process.env.GROQ_API_KEY) {
try {
const groqReply = await handleGroqChat(message, history);
return NextResponse.json({ reply: groqReply, provider: "groq" });
} catch (groqError: any) {
console.error("Groq Primary Error:", groqError.message);
// Execution falls through to Gemini
}
}
// Fallback engine
const geminiReply = await fallbackToGemini(message, history, apiKey);
return NextResponse.json({ reply: geminiReply, provider: "gemini_failover" });The provider field in the response allows the frontend to notify the user transparently via a toast, without breaking the conversation flow.
Tradeoff: Two providers means two SDKs, two system prompt formats, and two tool-calling implementations to maintain. The added complexity is justified by the reliability guarantee.
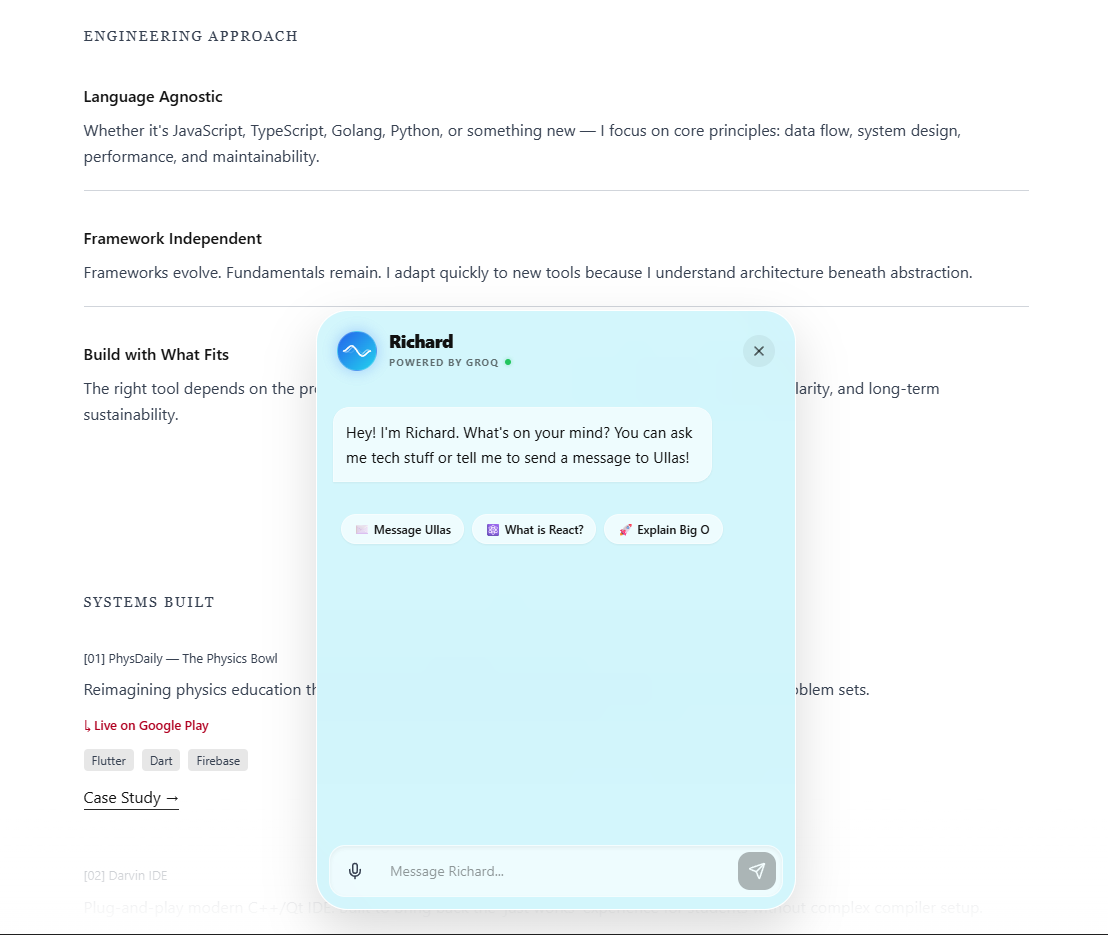
3. LLM Tool Calling: From Chat to Action
Problem: A chatbot that only answers questions has limited utility. Visitors should be able to take meaningful action — such as sending a message to the developer — without leaving the conversation.
Decision: Both providers are configured with a send_message_to_ullas function declaration. When a visitor expresses intent to contact, the LLM collects the sender's email and message through natural conversation, then triggers the tool call. The server executes the function by sending a real email via NodeMailer and Gmail SMTP.
This is the critical difference between a demo chatbot and a functional assistant. The AI does not just respond — it orchestrates server-side actions with real-world effects.
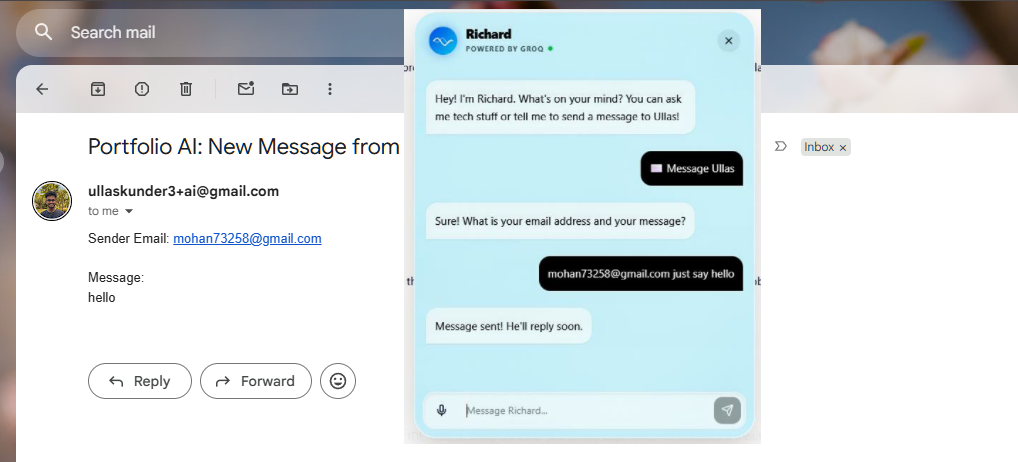
Tradeoff: Tool calls require careful prompt engineering to prevent false triggers. The tool description explicitly states it should only fire after the user provides both their email and message.
4. Frontend State Management: Hook-Based Architecture
Problem: Mixing API logic directly into React components creates tightly coupled, hard-to-test code.
Decision: All conversation state is encapsulated in a useGeminiAgent custom hook, which exposes a clean interface: messages, isLoading, sendMessage, and provider. The component tree never touches fetch directly.
Messages are modeled as typed objects rather than plain strings:
export type Message = {
id: string;
role: "user" | "ai";
text: string;
};This enables optimistic UI updates — the user's message object is appended to state immediately on send, before the API responds. The conversation feels instant even when network latency is high.
When the backend switches to the fallback engine, the hook detects the provider: "gemini_failover" flag and triggers a non-blocking toast notification. The user is informed but never interrupted.
Tradeoff: The hook currently manages both API communication and UI state. At greater complexity, these concerns could be split into separate hooks or migrated to a state machine (e.g., XState).
5. Rate Limiting: Protecting a Public Endpoint
Problem: A public AI endpoint without rate limiting is an open invitation for abuse — automated scripts can drain API quotas and inflate costs.
Decision: An in-memory Map<string, { count, lastReset }> tracks requests per IP address. The limit is set to 5 requests per 60-second window. Exceeding the limit returns a 429 Too Many Requests response with a user-friendly message.
const rateLimitMap = new Map<string, { count: number; lastReset: number }>();
const RATE_LIMIT = 5;
const TIME_WINDOW = 60 * 1000; // 1 minute
if (rateData.count >= RATE_LIMIT) {
return NextResponse.json(
{ reply: "Whoa, slow down there! Give me a minute to catch my breath." },
{ status: 429 },
);
}Tradeoff: In-memory storage is simple but ephemeral — it resets on every serverless cold start and does not share state across multiple instances. This is addressed in the "Scaling Considerations" section below.
6. Voice Input: Web Speech API Integration
A useSpeechRecognition hook wraps the browser's native Speech Recognition API. It runs in continuous mode with interim results, and uses a 1500ms silence timer to detect when the user has finished speaking. On silence, the accumulated transcript is automatically sent to the AI.
The hook also handles edge cases: microphone permission denial, no-speech timeouts with auto-restart, and pausing the mic while the AI response is in flight to prevent feedback loops.
A companion useSound hook provides auditory feedback (message sent/received sounds), adding a tactile quality to the interaction.
The next evolution of this feature is a Claude-style conversational handoff — a fully interruptible audio experience built on the Web Audio API. That architecture warrants its own deep dive, which will be covered in detail in an upcoming post.
Scaling Considerations: What Changes at Production Scale
The current implementation is intentionally scoped for a single-instance portfolio deployment. Here is what would change in a production environment:
| Component | Current | At Scale |
|---|---|---|
| Rate Limiter | In-memory Map (resets on cold start) |
Redis-backed (e.g., Upstash) with sliding window |
| Conversation History | Client-side state, sent with each request | Server-side session store or database |
| Failover | Sequential try/catch | Circuit breaker pattern with health checks |
| System Prompt | Hardcoded string | Version-controlled prompt registry |
| Monitoring | console.error |
Structured logging + alerting (e.g., Sentry, Datadog) |
These are deliberate engineering choices, not oversights. For a portfolio-scale deployment, the current approach optimizes for simplicity and fast iteration. Knowing when to introduce additional complexity is as important as knowing how.
Closing
The complete implementation — API route, custom hooks, and configuration — is deployed and available for review on my portfolio. I welcome any questions or discussion about the architecture, design tradeoffs, or potential improvements.